Docker Swarm and GlusterFS
Views: 9695
After Evaluation, I recommend using docker swarm instead of kubernetes. Docker swarm is now integrated in docker, so it fits perfectly the need when using docker, and moreover it is extremely simple to use and maintain.
Do not use GlusterFS! It is extremely slow and very unstable! I am now going to remove my glusterfs and to evaluate new filesystems.
Docker swarm is a cluster management system that allows to deploy docker containers to several nodes. So it is a direct replacement of kubernetes. Docker swarm allows to easily build a cluster of several nodes running docker services on Ubuntu 16.04. Initial setup is trivial, but local volumes are not shared across the nodes, so when a container is moved to another service, the volumes are empty, the content is not migrated. An easy solution for this is to use glusterfs to replicate the same data on all the nodes.
This is my intended docker swarm setup, distributed over two locations (I’ll use labels to bind the services to a location):
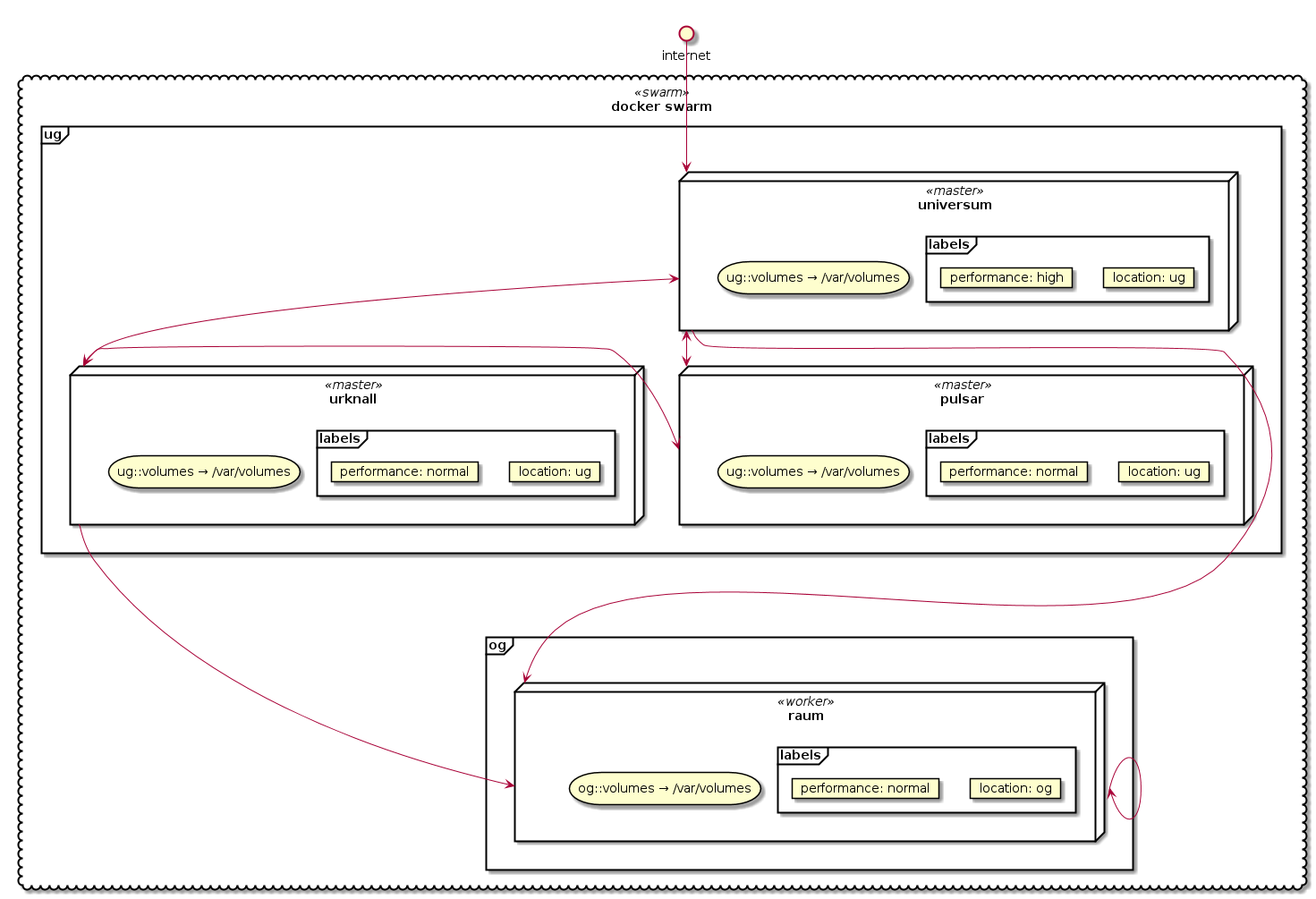
This is my intended gluster setup, each location has it’s own volumes volume and replicates the volumes of the other:
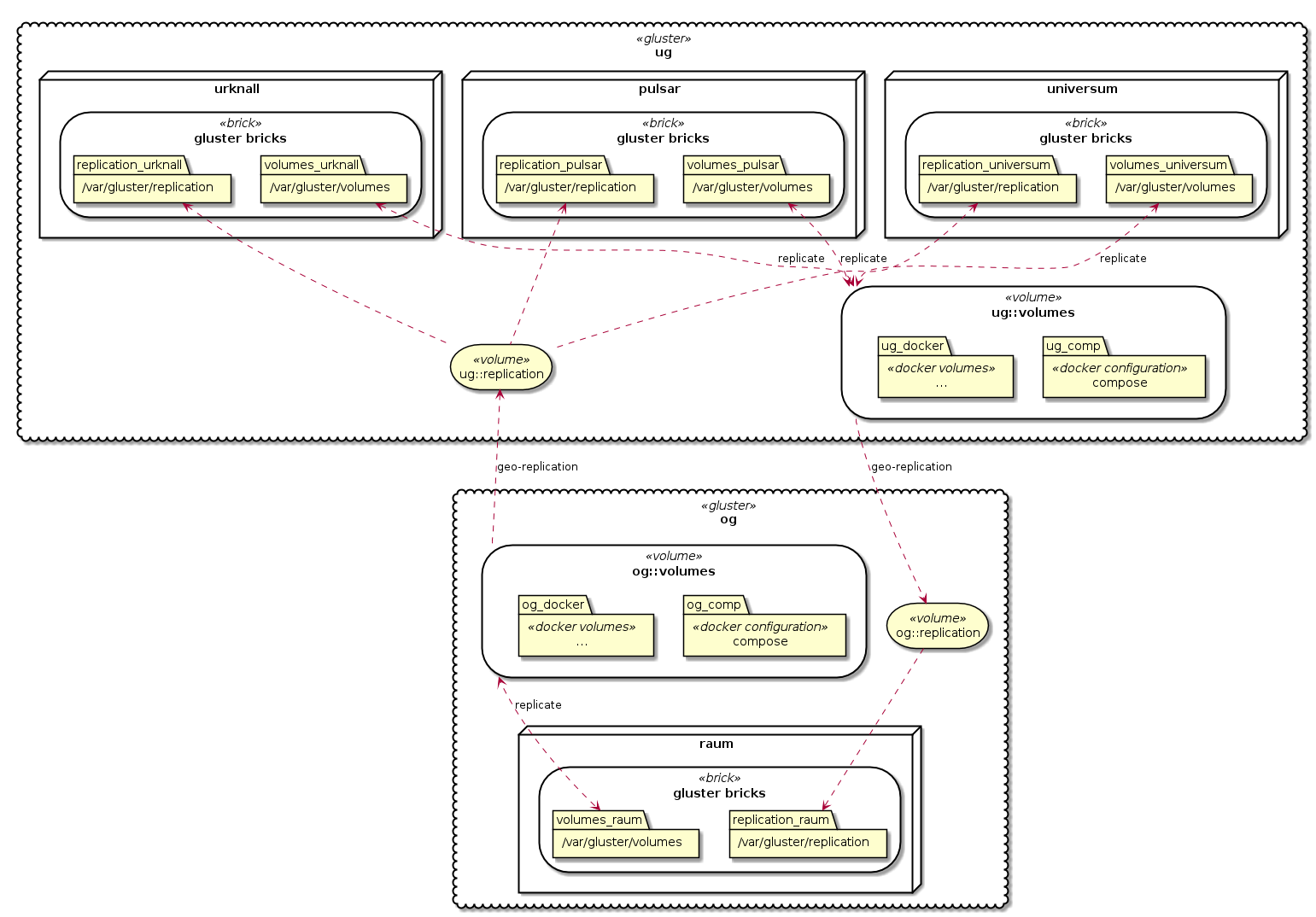
Basic Installation
On all involved servers, install glusterfs and docker server (without attr, you get the error message from glusterfs: getfattr not found, certain checks will be skipped
) (check which is the latest release of gluster in the repository, at the time of writing, it was 3.12):
sudo add-apt-repository ppa:gluster/glusterfs-3.12 wget -qO- https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -sudo add-apt-repository"deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" sudo apt-get update sudo apt-get install ntp glusterfs-server python-prettytable attr docker-ce lxc-docker- docker-engine- docker.io-sudosed -i '1{s,#!/bin/sh,#!/bin/bash,p}' /sbin/mount.glusterfs
Log out, then log in again to get the new group, or simply run su - $(whoami) or ssh localhost.
The last line is a bugfix, otherwise mounting a gluster volume fails, at least in glusterfs 3.12.
Start With One Node
- Hostname
- master
- IP
- 172.16.0.24
Often am installation starts with only one server, that means one node, but it should be flexible to add more nodes later. Each server runs a glusterfs node and a docker swarm node. The first server also runs the docker swarm manager.
Setup GlusterFS For Volumes
All glusterfs data shall be in subdirectories of /var/gluster, there shall be a glusterfs volume containing all shared docker volumes in /var/gluster/volumes. This will be mounted on /var/volumes on every docker swarm node, from where it will be used in docker swarm.
Create the directories on master, create the glusterfs volume, limit access to localhost (127.0.0.1), start and mount it:
sudo mkdir -p /var/gluster/volumes /var/volumes
sudo gluster volume create volumes $(hostname):/var/gluster/volumes force
sudo gluster volume set volumes auth.allow 127.0.0.1
sudo gluster volume start volumes
sudo tee -a /etc/fstab <<EOF
localhost:/volumes /var/volumes glusterfs defaults,_netdev,noauto,x-systemd.automount,noatime,nodiratime 0 0
EOF
sudo mount /var/volumes
Parameter force is necessary, if /var/gluster is on the root file and not in a separate mount point. To mount /var/volumes on boot, mount parameter are appended to /etc/fstab.
Test
Optionally you can test the glusterfs setup: Store a file in /var/volumes and it should also appear in /var/gluster/volumes:
echo "Hello World" | sudo tee /var/volumes/test.txt cat /var/volumes/test.txt ls -l /var/gluster/volumes cat /var/gluster/volumes/test.txt
Initialize Docker Swarm Master
Configuring docker swarm is very easy, just run:
docker swarm init --advertise-addr 172.16.0.24
The option --advertise-addr is necessary to specify the external address of the cluster, if you have more than one network interfaces running.
That’s all. The docker swarm init command outputs the command how other nodes may join the cluster. You will need it, when you add a node. If you forget it, then simply run docker swarm join-token worker.
Add A Node
- Hostname
- node1
- IP
- 172.16.0.25
When you add a node, you need to fulfill two steps:
- extend your glusterfs to replicate to the new node
- add new node to the docker swarm
Extend GlusterFS To Replicate On New Node
On node1 create the pathes:
sudo mkdir -p /var/gluster/volumes /var/volumes
sudo tee -a /etc/fstab <<EOF
localhost:/volumes /var/volumes glusterfs defaults,_netdev,noauto,x-systemd.automount 0 0
EOF
On master add the new node, run:
sudo gluster peer probe 172.16.0.25 sudo gluster volume add-brick volumes replica 2 172.16.0.25:/var/gluster/volumes force
Now that it is ready, mount it on the new node, on node1 run:
sudo mount /var/volumes
Test
Again, you can optionally test the cluster replication. If you did the test above, then /var/volumes/test.txt should also exist on the new node, and after a short time, it should be replicated in /var/gluster/volumes, so on host node1, run:
ls -l /var/volumes cat /var/volumes/test.txt ls -l /var/gluster/volumes cat /var/gluster/volumes/test.txt
Now you can either keep /var/volumes/test.txt or remove it either on any of the two servers. Removal should then also be propagated to both.
Add Worker Node To Docker Swarm
Add new node to the swarm master by calling on the new node node1 the command given on the master at initialization, something like:
docker swarm join --token … 172.16.0.24:2377
If you forgot the command, login to master and run docker swarm join-token worker. To add an additional manager, simply replace worker by manager when you get the token: swarm join-token manager.
Combine Docker Swarm and GlusterFS
As an example, let’s create a nextcloud in a docker service that stores data persistently in our glusterfs. In my example, I have two swam nodes and four glusterfs nodes, three are connected on a gigabit ethernet switch, one is in another floor, connected through gigabit powerline.
This is the docker compose file mrw-cloud.yaml:
version: '3.3' services: mysql: image: mysql:latest volumes: - type: bind source: /var/volumes/mrw-cloud/mysql target: /var/lib/mysql environment: - 'MYSQL_DATABASE=nextcloud' - 'MYSQL_USER=nextcloud' - 'MYSQL_PASSWORD=SomeSecretPassword' - 'MYSQL_ROOT_PASSWORD=SomeSecretRootPassword' nextcloud: image: mwaeckerlin/nextcloud:latest ports: - 8001:80 environment: - 'MYSQL_PASSWORD=SomeSecretPassword' - 'MAX_INPUT_TIME=7200' - 'URL=mrw.cloud' - 'ADMIN_PWD=GuiAdministrationPassword' volumes: - type: bind source: /var/volumes/mrw-cloud/config target: /var/www/nextcloud/config - type: bind source: /var/volumes/mrw-cloud/data target: /var/www/nextcloud/data
As specified above,, the gluster volume is mounted in /var/volumes/, so create the pathes and deploy the service:
sudo mkdir -p /var/volumes/mrw-cloud/{mysql,config,data}
docker stack deploy --compose-file mrw-cloud.yaml mrw-cloud
Then after a while, I can access it at port 8001 on any swarm node. This is a real life example (with other passwords of course) for: https://mrw.cloud
Geo Replication
With geo replication, you replicate a volume from a group of master nodes in one direction over a slower connection to a replication volume on a group of slave nodes. Follow the instruction on the gluster documentation:
Setup Passwordless SSH
All master nodes need password-less ssh access to a special replication user on all slave nodes. Just setup a normal ssh key exchange:
On all of the master nodes do the following, copy the key (end the root-session with ctrl-d):
sudo chmod go= /var/lib/glusterd/geo-replication/secret.pem sudo cat /var/lib/glusterd/geo-replication/secret.pem.pub
Copy the above key content of ~root/.ssh/id_rsa.pub to all of the slave nodes and paste it at the cat command below (end the root-session with ctrl-d):
sudo useradd -m replication sudo -Hiu replication mkdir .ssh cat > .ssh/authorized_keys
Configure Replication Target On Slaves
On on slave nodes create target volume, respectively add new slave bricks to the target. Then configure gluster-mountbroker which is responsible for mounting the target volume as non priviledged user on the replication slave:
sudo gluster volume create replication $(hostname):/var/gluster/replication force sudo gluster volume start replication sudo gluster-mountbroker add replication replication sudo mkdir -p /var/replication sudo gluster-mountbroker setup /var/replication replication sudo gluster-mountbroker statussudo /usr/lib/x86_64-linux-gnu/glusterfs/set_geo_rep_pem_keys.sh replication volumes replication
Setup Replication On A Master
sudo gluster volume geo-replication volumes replication@slave1::replication config remote_gsyncd $(dpkg -S '*/gsyncd' | sed 's,.* ,,') sudo gluster volume geo-replication volumes replication@slave1::replication create push-pem sudo gluster volume geo-replication volumes replication@slave1::replication start
Simply add option force after push-pem, if you get the error message:
Total disk size of master is greater than disk size of slave. Total available size of master is greater than available size of slave geo-replication command failed
Check
On master, run:
sudo gluster volume geo-replication volumes replication@raum::replication status
The result should be something like this:
MASTER NODE MASTER VOL MASTER BRICK SLAVE USER SLAVE SLAVE NODE STATUS CRAWL STATUS LAST_SYNCED -------------------------------------------------------------------------------------------------------------------------------------------------------- universum volumes /var/gluster/volumes replication replication@raum::replication raum Passive N/A N/A urknall volumes /var/gluster/volumes replication replication@raum::replication raum Passive N/A N/A pulsar volumes /var/gluster/volumes replication replication@raum::replication raum Active Hybrid Crawl N/A
If you see errors only, check if all gluster-processes are correctly running. Terminate all, kill eventually not terminated processes, and then restart them all. Or simply reboot masters and/or slaves. I did something like:
sudo -Hi systemctl status glusterd.service glustereventsd.service glusterfs-server.service glusterfssharedstorage.service systemctl stop glusterd.service glustereventsd.service glusterfs-server.service glusterfssharedstorage.service pkill gluster pkill -9 gluster systemctl start glusterd.service glustereventsd.service glusterfs-server.service glusterfssharedstorage.service systemctl status glusterd.service glustereventsd.service glusterfs-server.service glusterfssharedstorage.service
Problems
Filesystem not mounted on reboot
Add noauto,x-systemd.automount to the /etc/fstab-line. Fount at: http://lists.gluster.org/pipermail//gluster-users/2016-October/028781.html
Geo Replication Faulty
I get e.g. this:
marc@raum:~$ sudo gluster volume geo-replication volumes replication@universum::replication status
MASTER NODE MASTER VOL MASTER BRICK SLAVE USER SLAVE SLAVE NODE STATUS CRAWL STATUS LAST_SYNCED
————————————————————————————————————————————————————
raum volumes /var/gluster/volumes replication replication@universum::replication N/A Faulty N/A N/A
In this case, check the logs, to monitor all logs, call sudo tail -c 0 -f $(sudo find /var/log/glusterfs -type f -name '*.log'). This showed me, that the ssh-command was not successful. I manually tried the same command, and yes, it uses another key than the one I setup for geo replication. And I got Load key "/var/lib/glusterd/geo-replication/secret.pem": bad permissions. So I updated the key and the documentation to fix this.
Peer Rejected
If sudo gluster peer status Shows State: Peer Rejected (Connected), then on the inolved nodes do:
cd /var/lib/glusterd sudo systemctl stop glusterfs-server.service sudo rm -rf bitd glustershd hooks options quotad snaps vols groups nfs peers scrub ss_brick geo-replication sudo systemctl start glusterfs-server.service sudo gluster peer probe … sudo systemctl restart glusterfs-server.service
Where … is the name (URL/IP) of the other node.
Performance Problem Remote Sync
Initial startup of mysql container lasts eight to ten minutes, if mysql is on glusterfs. If the database is created locally in /var/tmp instead of in /var/volumes, then it lasts two minutes, So it is five times slower on glusterfs. Probably it is slow due to remote replication over powerline, so I removed that brick and tried again, and was ready in less than two minutes. So replication must be avoided over high latency slow lines (well it’s not that slow, but slower than gigabit ethernet). You can use geo replication instead to synchronize to a remote location for backup purposes.
Stability Problem Btrfs Snapshots
Btrfs allows snapshots, so my initial backup concept was to mirror all disks on each node, plus btrfs snapshots on each node for the timeline. That was a miserable failure. Every day, when btrfs snapshot was executed, glusterfs broke down and took hours to recover. So I disabled btrfs snapshots.
General Performance Problems
Access is very slow. Sometimes mysql crashes. After a crash, it lasts hours and hours until the database is back again. I don’t know what’s the problem and neither how I could fix it. Obviousely, it is a glusterfs problem — perhaps in combination with btrfs? Perhaps, I should try with ZFS?
I found some performance tuning tipps for glusterfs and readdir that I’ll try:
sudo gluster volume set volumes performance.cache-size 1GBsudo gluster volume set volumes cluster.readdir-optimize on- sudo gluster volume set volumes nfs.trusted-sync on
- performance.cache-size: 1GB
- performance.io-thread-count: 16
- performance.write-behind-window-size: 8MB
- performance.readdir-ahead: on
- client.event-threads: 8
- server.event-threads: 8
- cluster.quorum-type: auto
- cluster.server-quorum-type: server
- cluster.server-quorum-ratio: 51%
- > Kernel parameters:
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_fin_timeout = 15
net.core.somaxconn = 65535
vm.swappiness = 1
vm.dirty_ratio = 5
vm.dirty_background_ratio = 2
vm.min_free_kbytes = 524288 # this is on 128GB RAM - …
The result is not better.
Sources
- Using GlusterFS with Docker swarm cluster
- Add and remove GlusterFS servers
- Geo Replication, better Geo Replication
- Performance tuning
sudo gluster volume geo-replication volumes replication@raum::replication config remote_gsyncd /usr/lib/x86_64-linux-gnu/glusterfs/gsyncd
Steffen am 18. Februar 2019 um 19:10 Uhr
Hallo Marc,
vielen Dank für den Artikel.
Ich implementiere gerade etwas Ähnliches und erspare mir hier vermutlich einiges an Forschung/Trial&Error …
Mein data liegt zwar in einem externem Storage und als DB nutze ich die Azure PostgeSQL, das HTML/config Verzeichnis soll aber aus Performance-Gründen lokal auf den Worker–Nodes liegen -> GlusterFS.
Mein Problem besteht aber im Session-Handling im Swarmbetrieb. Da die Docker-Instanzen «stateless» sind, sterben die Nutzer bei jedem Wechsel auf einen anderen Cluster-Knoten, da Nextcloud die Sessions nur lokal (im RAM ???) vorhält. Und das passiert eigentlich permanent.
Hast Du im Swarm mehrer Replicas laufen und wenn ja, wie?
Mit freundlichen Grüßen
Steffen
Marc Wäckerlin am 6. März 2019 um 08:43 Uhr
Ich habe bisher nur Replicas von «Stateless» Instanzen, namentlich Reverse-Proxy, Bind, Monitoring, etc.